

これまでパラメトリックとノンパラメトリックの違い、対応のある/なし、エクセルやEZRでできるt検定などに関して記事にしてきました。
今回はノンパラメトリックで対応のある2群間のデータの時に使う検定の一つ、ウィルコクソン(Wilcoxon)の符号付順位和検定をEZRで算出していきます。
ウィルコクソンの符号付順位検定とは?
ウィルコクソンの符号付順位検定は、対応のある2群のデータで、母集団がノンパラメトリックの時に用いるものです。
対応のある/ない、パラメトリックとノンパラメトリックの違いなどに関しては以前の記事を参照してください。
で、ここで注意点ですが、似たような名前の統計手法にウィルコクソンの順位和検定(マン・ホイットニー(Mann-Whitney)のU検定とも言う)という統計手法がありますが.これらは別物です。
2つの統計手法の共通点と相違点を説明すると、どちらの手法も2群のデータ間における中央値の差を検定する手法ですが、ウィルコクソンの符号付順位和検定は2群間のデータに対応があるときに用います。
ウィルコクソンの順位和検定(マン・ホイットニーのU検定)は対応のない2群のデータで、母集団がノンパラメトリックの時に用います。
EZRでウィルコクソンの符号付順位検定を算出してみよう!
ここからは実際にEZRを使ってウィルコクソンの符号付順位検定を算出していきます。
使うデータは以前エクセルでウィルコクソンの符号付順位検定を算出した時に用いたものを使用します。
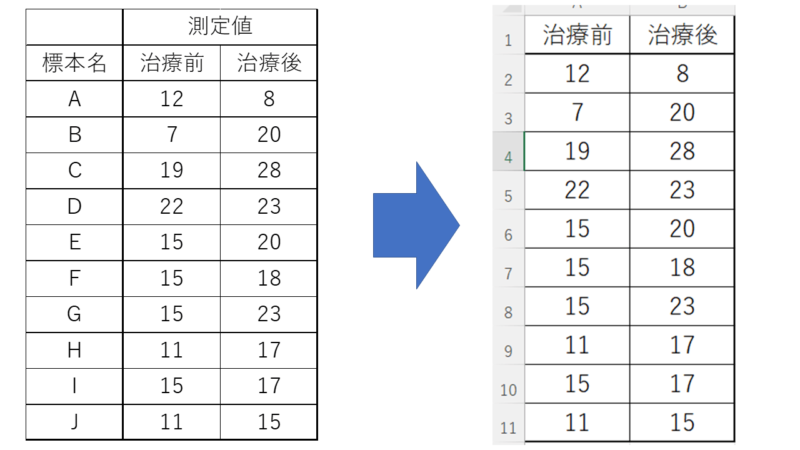
※以前の記事でも記載していますが、対応のある時のデータ配置と、対応のない時のデータ配置の違いは、きっちり押さえておきましょう。
次にデータを読み取ります。「ファイル」→「データのインポート」→「ファイルまたはクリップボード, URLからテキストデータを読み込む」を選びます。
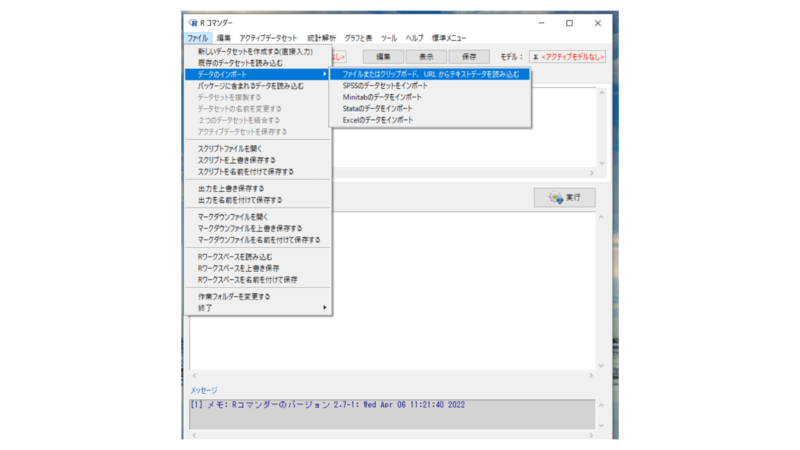
この時データセット名(赤枠)はなんでも大丈夫です。今回はそのままにしておきます。
もしクリップボード、もしくはテキストを読み込む場合は下図のように(赤枠)、カンマではなくタブを選択しましょう。
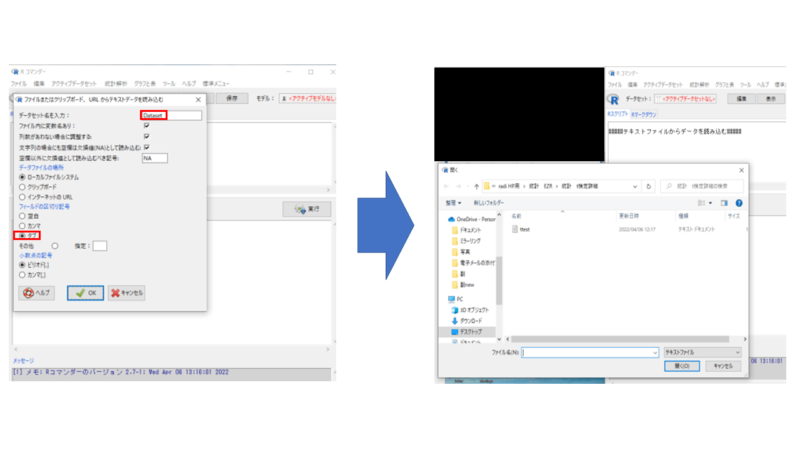
読み込みが終わったら、正常に読み込めているか確認します。
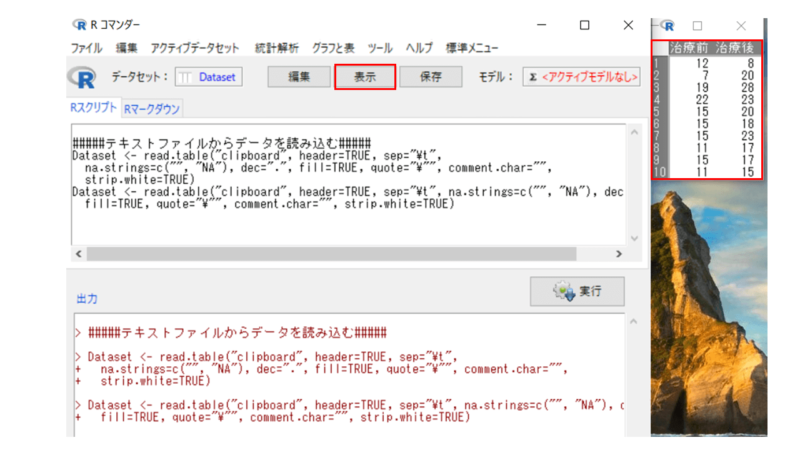
データセットの部分が、先ほど変更した名称になっているか確認し、その後「表示」を選択します。表示されたデータが正しければOKです。
データを解析していきます。今回は対応のないパラメトリックデータなので、
「統計解析」→「ノンパラメトリック検定」→「対応のある2群間の比較(Wilcoxon符号付順位和検定)」を選びます。
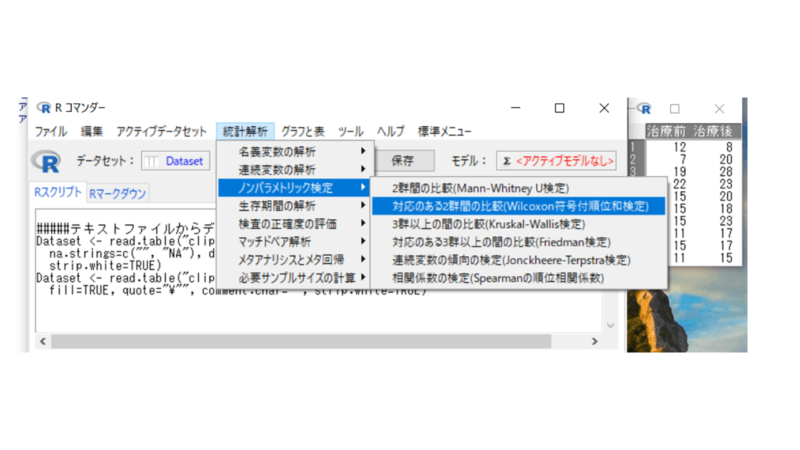
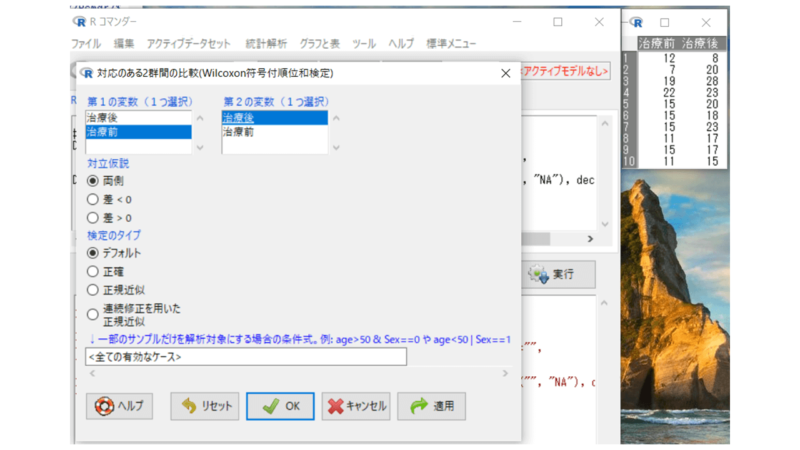
目的変数(1つ選択)で「治療前」を、比較する群(1つ以上選択)で「治療後」を選択します。
対立仮説は「両側」を、検定のタイプは「デフォルト」、他はそのままで算出します。
結果が出ました。
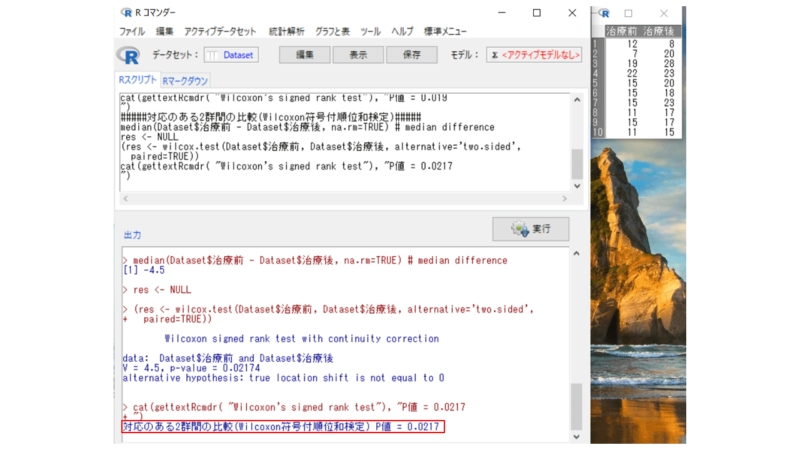
p=0.0217、以前エクセルで求めた結果はp=0.019なので少し数値が違いますが、これは検定タイプの差による影響です。
検定タイプを「デフォルト」から「正規近似」にしてみましょう。
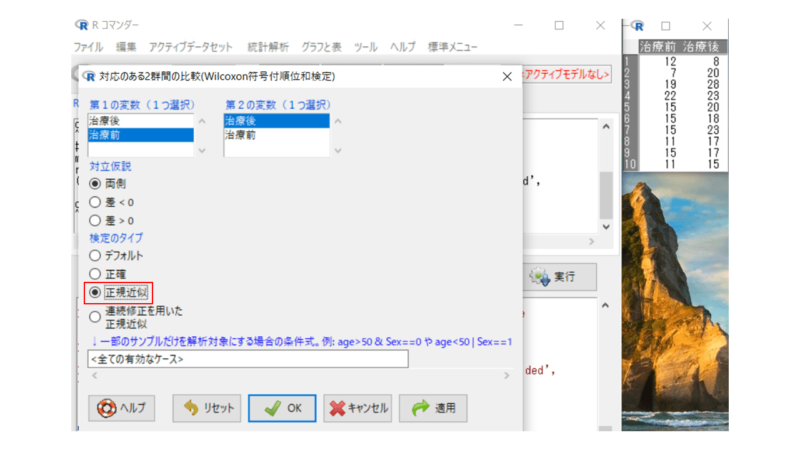
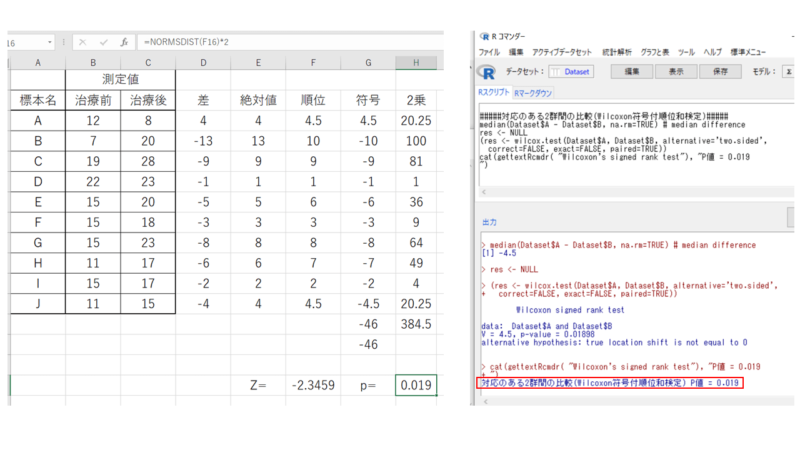
p=0.019となり、以前エクセルで求めた結果と同じになりましたので間違いなさそうです。
もしエクセルで算出した結果と比べる場合は検定のタイプを「正規近似」にしましょう。
対応のあるノンパラメトリックの2群間データに用いよう!
ウィルコクソンの符号順位検定は、対応のある2群のデータで、母集団がノンパラメトリックの時に用いるものです。
マン・ホイットニー(Mann-Whitney)のU検定は対応のない2群のデータで、母集団がノンパラメトリックの時に用います。
この2つの違いをきちんと認識し、データに適した統計手法を選択しましょう。


コメント