

以前の記事で正規分布かつ対応のある2群間のデータに対し、対応のあるt検定をEZRで算出しました。

今回は正規分布かつ対応のない2群間のデータに対し、EZRで対応のないt検定を算出する方法を具体的に解説していきます。
EZRで解析するためのデータを作成する
今回も以前のエクセルでt検定する方法の記事で使用したデータを例として示します。
前回の対応のあるt検定を解析する場合と、対応のないt検定を解析する場合はデータの並べ方が異なりますので注意してください。間違うと読み込まなかったり、間違った値が算出されたりしまいます。
では、実際に操作をしながら順に説明していきます。まずデータを下図のように変更します。
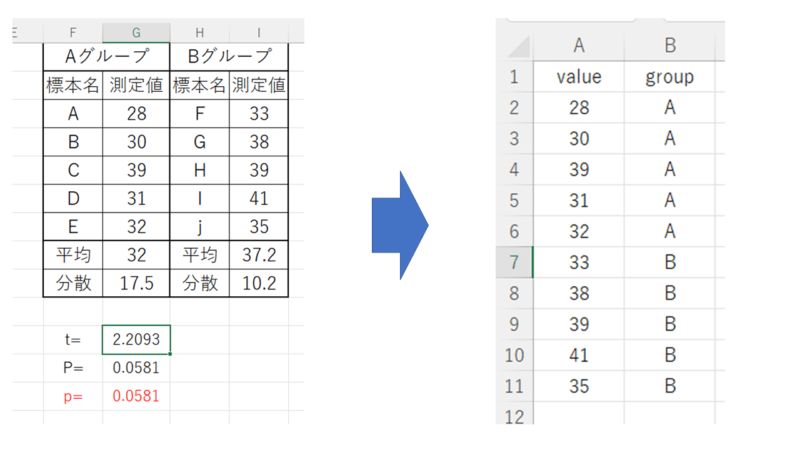
並べ替えたら保存しておきましょう。この時、他にデータがあると読み取りがうまくいかなかったりしますので、表示されているデータ以外は消しておきます。
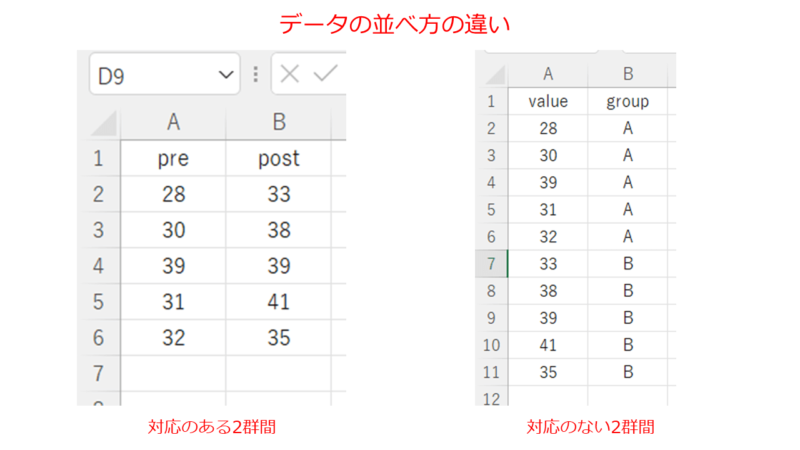
※ちなみに前回の対応のあるt検定の時のデータ配置と、今回の対応のないt検定の時のデータ配置の違いを下図に示します。データ配置の違いを押さえておきましょう。
次にデータを読み取ります。「ファイル」→「データのインポート」→「ファイルまたはクリップボード, URLからテキストデータを読み込む」を選びます。
この時データセット名(赤枠)はなんでも大丈夫です。今回はそのままにしておきます。
もしクリップボード、もしくはテキストを読み込む場合は下図のように(赤枠)、カンマではなくタブを選択しましょう。
読み込みが終わったら、正常に読み込めているか確認します。
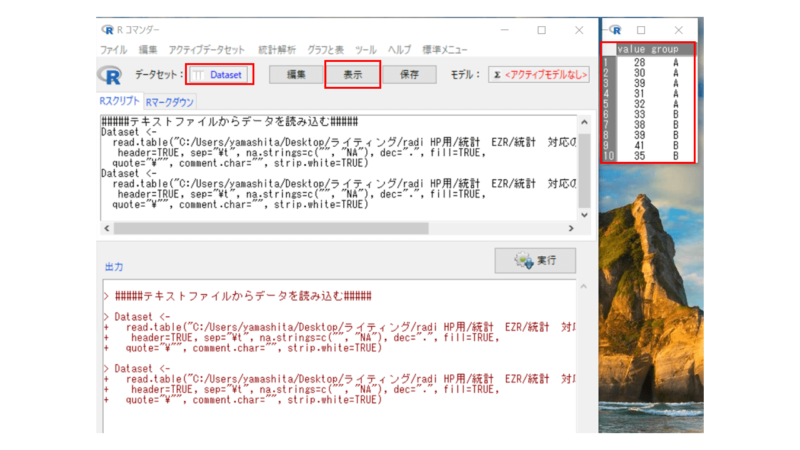
データセットの部分が、先ほど変更した名称になっているか確認し、その後「表示」を選択します。表示されたデータが正しければOKです。
データを解析していきます。今回は対応のないt検定なので、
「統計解析」→「連続変数の解析」→「2群間の平均値の比較(t検定)」を選びます。
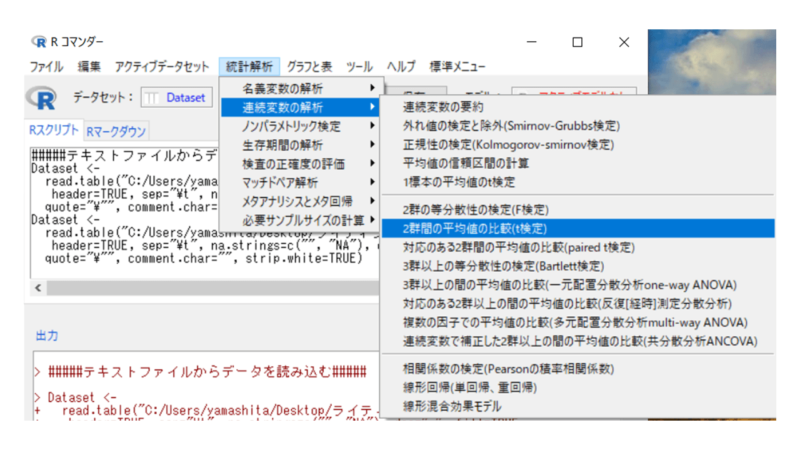
この例において、目的変数(どの値をみるか)は 「value」、比較する群は 「group」 にします。
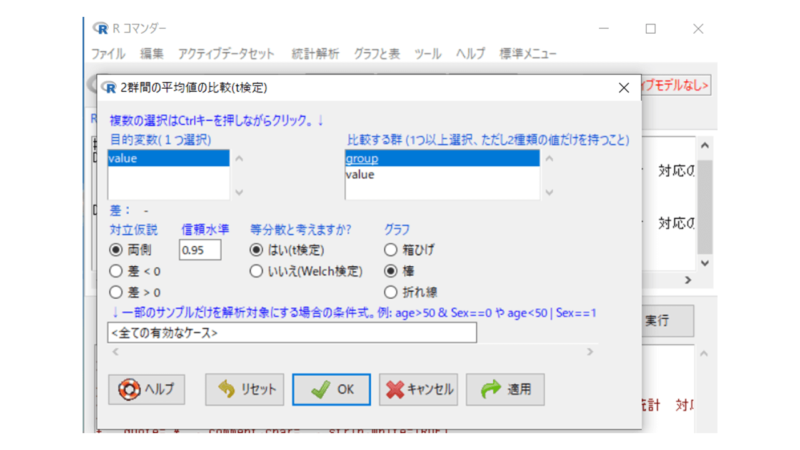
※2群が等分散でない場合は「等分散と考えますか?」の部分は「いいえ(Welch検定)」を選択しておきましょう。
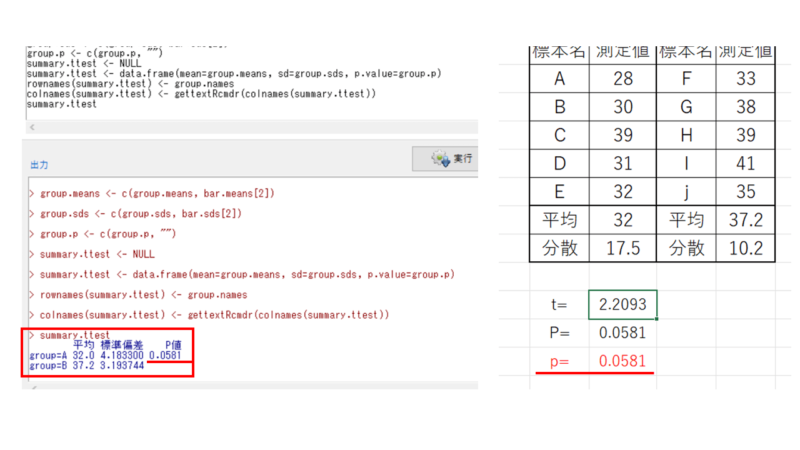
結果が出ました。
p=0.0581でp>0.05となり、有意差なしと判断されます。
以前エクセルで求めた結果と同じになりましたので間違いなさそうです。
※等分散性を確認したい場合(F検定)
ここで、分散を確認したい場合(F検定)についても触れておきます。
一応復習ですが、分散とは「データが平均値からどの程度散らばっているか」を表現するものです。
そしてt検定を行う条件として、2群が
・正規分布であること
・等分散であること
が挙げられます。
そこで、先ほどのデータを用いて等分散性の検定(F検定)をEZRで算出してみます。
「統計解析」→「連続変数の解析」→「2群の等分散性の検定(F検定)」
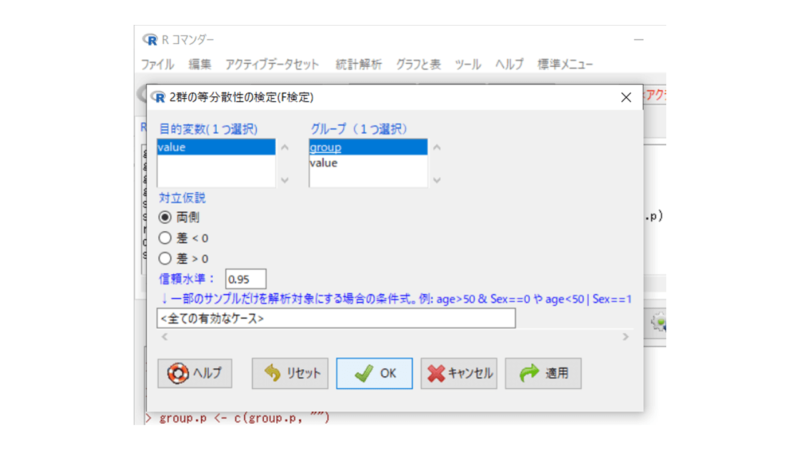
目的変数は 「value」、比較する群は 「group」 にします。
結果が出ました。
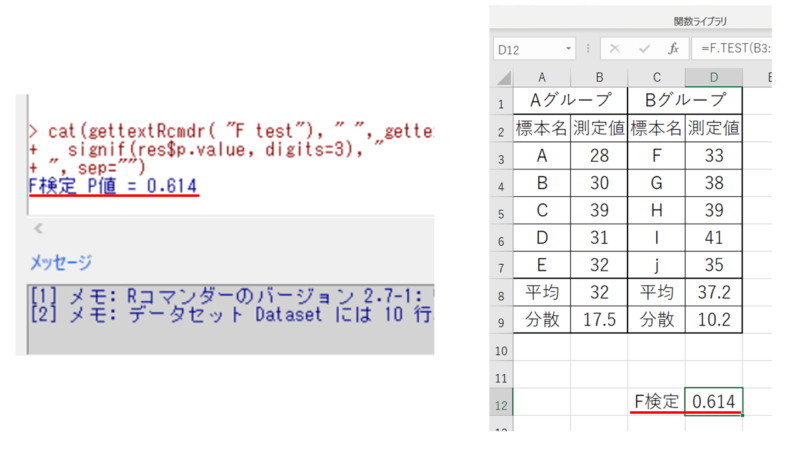
p=0.614、以前の記事でエクセルでの算出値と同じですので間違いなさそうです。
※ちなみにF検定はP<0.05の場合に等分散性が棄却されるので、今回は棄却されませんでした。つまり等分散性は否定されなかった、となります。
データの配置には気を付けよう!
今回の例のように無料統計解析ソフトEZRは、統計解析の種類によってデータ配置が決まっています。それぞれの統計解析に合ったデータ配置を覚えておきましょう。
また、EZRで求めた値があっているか、間違っていないかをエクセルなどで解析、算出した結果と比較し、可能な限りダブルチェックすることをおすすめします。


コメント
対応のあるt検定をしたいのですが(beforeとafterで前後を分類しています)、第一の変数と第二の変数には、beforeの変数しか出力されず、beforeとafterの比較ができません。何か原因はわかりますか?
実際のデータを見ていないので何とも言えませんが、対応のあるデータを解析する場合のデータ配列はあっているでしょうか?対応のない場合は縦一列で、データを並べますが、対応がある場合はbeforeとafterそれぞれの列(2列)にしてデータを並べます。
データの並べ方があっているなら、読み込みの問題だと思いますので、クリップボードから読み込んでみたり、エクセルで読み込んでみたりしてください。
それでも無理な様なら、少し手間ですが、beforeデータを読み込んだのち、データ編集でafterを手動で列を追加してデータを打ち込むという手もあります。
対応のあるt検定に関しては、「EZRで対応のあるt検定を算出してみよう!」(https://radi-toko.com/ezr-paired-ttest/)の記事も参照していただければ以下と思いますわかりやすいと思います。
どうしてもうまくいかない場合は「t検定の対応あり/なしの算出方法の違いに関して理解しよう!」https://radi-toko.com/t-test1/
もしくは「エクセルでできる!t検定の使い方、選び方と具体的な分析方法」https://radi-toko.com/t-test2/#toc1
を参考にEZRではなく、エクセルで求める方法を試してみてください。